Google’s recent announcement of the Gemini API marks a transformative leap in artificial intelligence technology. This cutting-edge API, developed by Google DeepMind, is a testament to Google’s commitment to advancing AI and making it accessible and beneficial for everyone. This blog post will explore the multifaceted features, potential applications, and impact of the Google Gemini API, as revealed in Google’s official blogs and announcements.
What is the Google Gemini?
Google Gemini is a highly advanced, multimodal artificial intelligence model developed by Google. It represents a significant step forward in AI capabilities, especially in understanding and processing a wide range of data types.
Gemini is a direct competitor to OpenAI’s GPT-3 and GPT-4 models. It differentiates itself through its native multimodal capabilities and its focus on seamlessly processing and combining different types of information. Its launch was met with significant anticipation and speculation, and it is seen as a crucial development in the AI arms race between major tech companies.
Below is a comparison of text and multimodal capabilities provided by Google, comparing Germi Ultra, which has not yet been officially launched, with Open AI’s GTP-4.
Key Features of Gemini
Multimodal Capabilities: Gemini’s groundbreaking design allows it to process and comprehend various data types seamlessly, from text and images to audio and video, facilitating sophisticated multimodal reasoning and advanced coding capabilities.
Three Distinct Models: The Gemini API offers three versions – Ultra, Pro, and Nano, each optimized for different scales and types of tasks, ranging from complex data center operations to efficient on-device applications.
State-of-the-Art Performance: Gemini models have demonstrated superior performance on numerous academic benchmarks, surpassing human expertise in specific tasks and showcasing their advanced reasoning and problem-solving abilities.
Diverse Application Spectrum: The versatility of Gemini allows for its integration across a wide array of sectors, including healthcare, finance, and technology, enhancing functionalities like predictive analytics, fraud detection, and personalized user experiences.
Developer and Enterprise Accessibility: The Gemini Pro is now available for developers and enterprises, with various features such as function calling, semantic retrieval, and chat functionality. Additionally, Google AI Studio and Vertex AI support the integration of Gemini into multiple applications.
The New Google Gemini API
The Gemini API represents a significant stride in AI development, introducing Google’s most capable and comprehensive AI model to date. This API is the product of extensive collaborative efforts, blending advanced machine learning and artificial intelligence capabilities to create a multimodal system. Unlike previous AI models, Gemini is designed to understand, operate, and integrate various types of information, including text, code, audio, images, and video, showcasing a new level of sophistication in AI technology.
Benefits for Developers and Creatives:
Gemini’s versatility unlocks a plethora of possibilities for developers and creatives alike. Imagine:
Building AI-powered applications: Germini can power chatbots, virtual assistants, and personalized learning platforms.
Boosting your creative workflow: Generate song lyrics, script ideas, or even marketing copy with Gemini’s innovative capabilities.
Simplifying coding tasks: Let Germini handle repetitive coding tasks or write entire code snippets based on your instructions.
Unlocking new research avenues: Gemini’s multimodal abilities open doors for exploring the intersection of language, code, and other modalities in AI research.
How to use the Google Germini API?
Using the Google Gemini API involves several steps and can be applied to various programming languages and platforms. Here’s a comprehensive guide based on the information from Google AI for Developers:
Setting Up Your Project
Obtain an API Key: First, create an API key in Google AI Studio or MakeSuite. Securing your API key and not checking it into your version control system is crucial. Instead, pass your API key to your app before initializing the model.
Initialize the Generative Model: Import and initialize the Generative Model in your project. This involves specifying the model name (e.g., gemini-pro-vision for multimodal input) and accessing your API key.
The Gemini API allows you to implement different use cases:
Text-Only Input: Use the gemini-pro model with the generateContent method for text-only prompts.
Multimodal Input (Text and Image): Use the gemini-pro-vision model. Make sure to review the image requirements for input.
Multi-Turn Conversations (Chat): Use the gemini-pro model and initialize the chat by calling startChat(). Use sendMessage() to send new user messages.
Streaming for Faster Interactions: Implement streaming with the generateContentStream method to handle partial results for faster interactions.
Germini Pro
Python
"""At the command line, only need to run once to install the package via pip:$ pip install google-generativeai"""import google.generativeai as genaigenai.configure(api_key="YOUR_API_KEY")# Set up the modelgeneration_config = {"temperature": 0.9,"top_p": 1,"top_k": 1,"max_output_tokens": 2048,}safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_HATE_SPEECH","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }]model = genai.GenerativeModel(model_name="gemini-pro",generation_config=generation_config,safety_settings=safety_settings)prompt_parts = ["Write a 10 paragraph about the Germini functionalities':",]response = model.generate_content(prompt_parts)print(response.text)
Germini Pro Vision
Python
"""At the command line, only need to run once to install the package via pip:$ pip install google-generativeai"""from pathlib import Pathimport google.generativeai as genaigenai.configure(api_key="YOUR_API_KEY")# Set up the modelgeneration_config = {"temperature": 0.4,"top_p": 1,"top_k": 32,"max_output_tokens": 4096,}safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_HATE_SPEECH","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT","threshold": "BLOCK_MEDIUM_AND_ABOVE" }]model = genai.GenerativeModel(model_name="gemini-pro-vision",generation_config=generation_config,safety_settings=safety_settings)# Validate that an image is presentifnot (img := Path("image0.jpeg")).exists():raiseFileNotFoundError(f"Could not find image: {img}")image_parts = [ {"mime_type": "image/jpeg","data": Path("image0.jpeg").read_bytes() },]prompt_parts = [ image_parts[0],"\nTell me about this image, what colors do we have here? How many people do we have here?",]response = model.generate_content(prompt_parts)print(response.text)
Implementing in Various Languages
The Gemini API supports several programming languages, each with its specific implementation details:
Python, Go, Node.js, Web, Swift, Android, cURL: Each language requires specific code structures and methods for initializing the model, sending prompts, and handling responses. Examples include setting up the Generative Model, defining prompts, and processing the generated content.
Further Reading and Resources
The Gemini API documentation and API reference on Google AI for Developers provide detailed information, including safety settings, guides on large language models, and embedding techniques.
For specific language implementations and more advanced use cases like token counting, refer to the respective quickstart guides available on Google AI for Developers.
By following these steps and referring to the detailed documentation, you can effectively utilize the Google Gemini API for various applications ranging from simple text generation to more complex multimodal interactions.
Germini vs. ChatGPT: The Ultimate Multimodal Mind Showdown
The world of large language models (LLMs) is heating up, and two titans stand at the forefront: Google’s Germini and OpenAI’s ChatGPT. Both boast impressive capabilities, but which one reigns supreme? Let’s dive into a head-to-head comparison.
Google Germini API – Pricing
Free for Everyone Plan:
Rate Limits: 60 QPM (queries per minute)
Price (input): Free
Price (output): Free
Input/output data used to improve our products: Yes
Pay-as-you-go Plan: ( will coming soon to Google AI Studio)
With 128k context, fresher knowledge, and the broadest set of capabilities, the GPT-4 Turbo is more potent than the GPT-4 and is offered at a lower price.
Multimodality: Germini shines in its ability to handle text, code, images, and even audio. This opens doors for applications like generating image captions or translating spoken language.
Function Calling: Germini seamlessly integrates into workflows thanks to its function calling feature, allowing developers to execute specific tasks within their code.
Embeddings and Retrieval: Gemini’s understanding of word relationships and semantic retrieval leads to more accurate information retrieval and question answering.
Custom Knowledge: Germini allows fine-tuning with your own data, making it a powerful tool for specialized tasks.
Multiple Outputs: Germini goes beyond text generation, offering creative formats like poems, scripts, and musical pieces.
Strengths of ChatGPT:
Accessibility: ChatGPT is widely available through various platforms and APIs, offering free and paid options. Germini is currently in limited access.
Creative Writing: ChatGPT excels in creative writing tasks, producing engaging stories, poems, and scripts.
Large Community: ChatGPT has a well-established user community that offers extensive resources and tutorials.
An experiment comparing the Germini and ChatGPT APIs applying the Sparse Priming Representations (SPR) technique
I conducted an experiment using the APIs from Open AI – ChatGPT and Google Germini, applying the technique(Sparse Priming Representations (SPR)) of prompt engineering to compress and decompress a text. Click here to access the experimental code I created in Google Colab.
The outcome was interesting; both APIs responded very well to the test. In the table below, we can observe a contextual difference, but both APIs were able to perform the task satisfactorily.
If you want to learn more about Sparse Priming Representations (SPR), I’ve written an entire post discussing it. Here it is below:
In the rapidly evolving landscape of artificial intelligence, the Google Gemini API represents a significant milestone. Its introduction heralds a new era where AI transcends traditional boundaries, offering multimodal capabilities far beyond the text-centric focus of models like ChatGPT. Google Gemini’s ability to process and integrate diverse data types — from images to audio and video — not only sets it apart but also showcases the future direction of AI technology.
While ChatGPT excels in textual creativity and enjoys widespread accessibility and community support, Gemini’s native multimodal functionality and advanced features like function calling and semantic retrieval position it as a more versatile and comprehensive tool. This distinction is crucial in an AI landscape where the needs range from simple text generation to complex, multimodal interactions and specialized tasks.
As we embrace this new phase of AI development, it’s clear that both ChatGPT and Google Gemini have unique strengths and applications. The choice between them hinges on specific needs and project requirements. Gemini’s launch is not just a technological breakthrough; it’s a testament to the ever-expanding possibilities of AI, promising to revolutionize various sectors and redefine our interaction with technology. With such advancements, the future of AI seems boundless, limited only by our imagination and the ethical considerations of its application.
On September 25th, 2023, OpenAI expanded the capabilities of its advanced model, GPT-4, by introducing the ability to interpret images and speech alongside text. Dubbed GPT-4V(ision) or GPT-4V, this feature catapults GPT-4 into the realm of multimodal models, offering a richer interaction experience by allowing visual question answering (VQA). Users can upload images, inquire about them, and even have GPT-4V assess context and relationships within the visuals, marking a significant stride toward a holistic understanding of textual and visual data and broadening the horizons for real-world applications of GPT-4.
The GPT-4V feature sets a new benchmark in AI by successfully bridging the gap between text and image understanding. This leap is imperative in evolving towards more intuitive and human-like interactions with machines. Through experiments, GPT-4V has showcased its potential in accurately interpreting and answering questions about various visual inputs, from understanding humor in memes to identifying currency types and even providing a high-level analysis of a movie from a mere image. This impressive ability opens up endless possibilities and applications, making GPT-4V a groundbreaking stride in the journey of AI.
What can I do with GPT-4 Vision?
Object Identification: GPT-4 Vision can accurately pinpoint objects and provide a detailed description by processing an image. Its recognition capabilities are spectacular, from everyday objects to complex machinery.
Text Transcription from Images: Say goodbye to manually typing text from an image. This feature allows users to seamlessly extract written or printed text from images, a boon for those dealing with vast documents or old archives.
Data Deciphering: Extract essential data from graphical content, such as charts, diagrams, and infographics, translating visual data into comprehensive text insights.
Multi-condition Processing: GPT-4 Vision is adept at analyzing images under multiple conditions. Whether understanding a photograph taken under varying lighting or discerning details in a cluttered scene, its analytical prowess is unmatched.
Educational Assistance: Students and educators can leverage GPT-4 Vision to analyze diagrams, illustrations, and visual aids, transforming them into detailed textual explanations, thus enhancing the learning process.
Coding Enhancement: For the tech-savvy, GPT-4 Vision can interpret visual code structures or flowcharts and translate them into actual coding languages, making the development process swifter and more efficient.
Design Understanding: For designers, understanding intricate patterns, layouts, or visual structures becomes easier. GPT-4 Vision can break down design elements and offer textual insights, aiding in refining and improving design concepts.
Click “Upgrade plan” under ChatGPT Plus in the pop-up.
Enter your payment information, then click “Subscribe”.
After payment, select “GPT-4” from the drop-down menu on your screen to use GPT-4 with ChatGPT.
Examples of Incredible Features You Can Do with GPT-4 Vision
Data Deciphering
It’s fantastic. I give this infographic with this prompt: “What does this tell you? Be very, very exact.“
Follow the results ChatGPT gave me.
This infographic provides insights into what SEO professionals believe will be the most significant disruptors to SEO performance in 2024. Here are the exact details:
Title and Context:
The title is “SEO Performance In 2024.”
SEO professionals were asked about what they thought would cause the most significant disruption to their SEO performance in the upcoming years.
Most Significant Disruption In SEO Performance:
Generative AI is perceived to be the top disruptor, with 21.0% of professionals identifying it.
E-E-A-T & Trusted Sources comes second with 13.5%. There’s a note mentioning that an extra “E” was added to E-A-T in December 2022, which stands for “Experience.”
Automation (Tools) is the third most significant disruptor at 10.7%.
Other factors listed in descending order of their perceived disruption potential are:
Core Web Vitals (8.2%)
Google Discover (6.4%)
Social Search (6.3%)
Structured Data (5.9%)
Site Security (5.3%)
Google Passages (4.2%)
Knowledge Graph and Entities (3.9%)
Video Search (3.6%)
SERP Features (3.5%)
Mobile SEO (2.8%)
Voice Search (2.6%)
None/Other (2.2%).
Visual Imagery:
There’s an image of a mobile phone with the ChatGPT logo on its screen.
Another visual element is a colorful wheel containing the letters E, E, A, T, and icons of various tech giants.
Additional Text Information:
SEO professionals have many new technologies and updates to consider for the year. Specifically, tools like ChatGPT and Google’s “Generative Search Experience” are mentioned as generating considerable interest and concern among these professionals.
In summary, the infographic emphasizes the rapidly evolving landscape of SEO, with new technologies, especially Generative AI, becoming significant factors that professionals in the field need to be aware of and adapt to.
Another example of extracting information from infographics with the same prompt: “What does this tell you? Be very, very exact.“
Certainly! The provided infographic conveys information about the usage patterns of social media among adults and teens. Here’s a detailed breakdown of the infographic’s contents:
Title: The infographic is titled “Adults vs Teens: How We Use Social Media.”
Background Information: The Pew Research Center released a study comparing the social media usage of adults and teens. The commentary mentions that teens today are inherently digital-savvy, having grown up in the digital era. However, when it comes to newer social platforms like Pinterest and Instagram, adults appear to have a slight edge in usage.
Overall Social Media Usage:
Adults: 72% of adults use social media.
Teens: 81% of teens use social media.
Platform-Specific Usage:
Facebook: Teens dominate the usage, with 94% of teens using it compared to 67% of adults.
Twitter: 26% of teens use Twitter, compared to 18% of adults.
Pinterest: 15% of adults use Pinterest, whereas only 1% of teens do.
Instagram: 13% of adults use Instagram, compared to 11% of teens.
Tumblr: 6% of adults use Tumblr, and 5% of teens use it.
Age Breakdown of Social Media Users:
Ages 13-18: 89% use social media.
Ages 18-29: 81% use social media.
Ages 30-49: 78% use social media.
Ages 50-64: 60% use social media.
Age 65+: 43% use social media.
Source: The data comes from Pew Research Center studies conducted in August 2013, May 2013, and February 2013.
Sponsor/Creator: The infographic was created by “NextAdvisor,” which offers in-depth, independent research.
In summary, the infographic suggests that while teens use social media platforms like Facebook more dominantly, adults are more inclined towards newer platforms like Pinterest and Instagram. The percentage of users also declines as the age group increases, with the youngest age group (13-18) having the highest percentage of users and the oldest age group (65+) having the lowest.
Text Transcription
Text Transcription from Images is instrumental when extracting texts from images. I used this prompt: “Can you extract the text from this image?“.
Another example with text transcription:
Educational Assistance
ChatGPT breaks down this diagram of a human cell for a 9th grader.
OpenAI released a paper outlining potential risks associated with the use of GPT-4V, which include:
Privacy risks from identifying people in images or determining their location, potentially impacting companies’ data practices and compliance. The paper notes that GPT-4V has some ability to identify public figures and geolocate images.
Potential biases during image analysis and interpretation could negatively impact different demographic groups.
Safety risks from providing inaccurate or unreliable medical advice, specific directions for dangerous tasks, or hateful/violent content.
Cybersecurity vulnerabilities such as solving CAPTCHAs or multimodal jailbreaks.
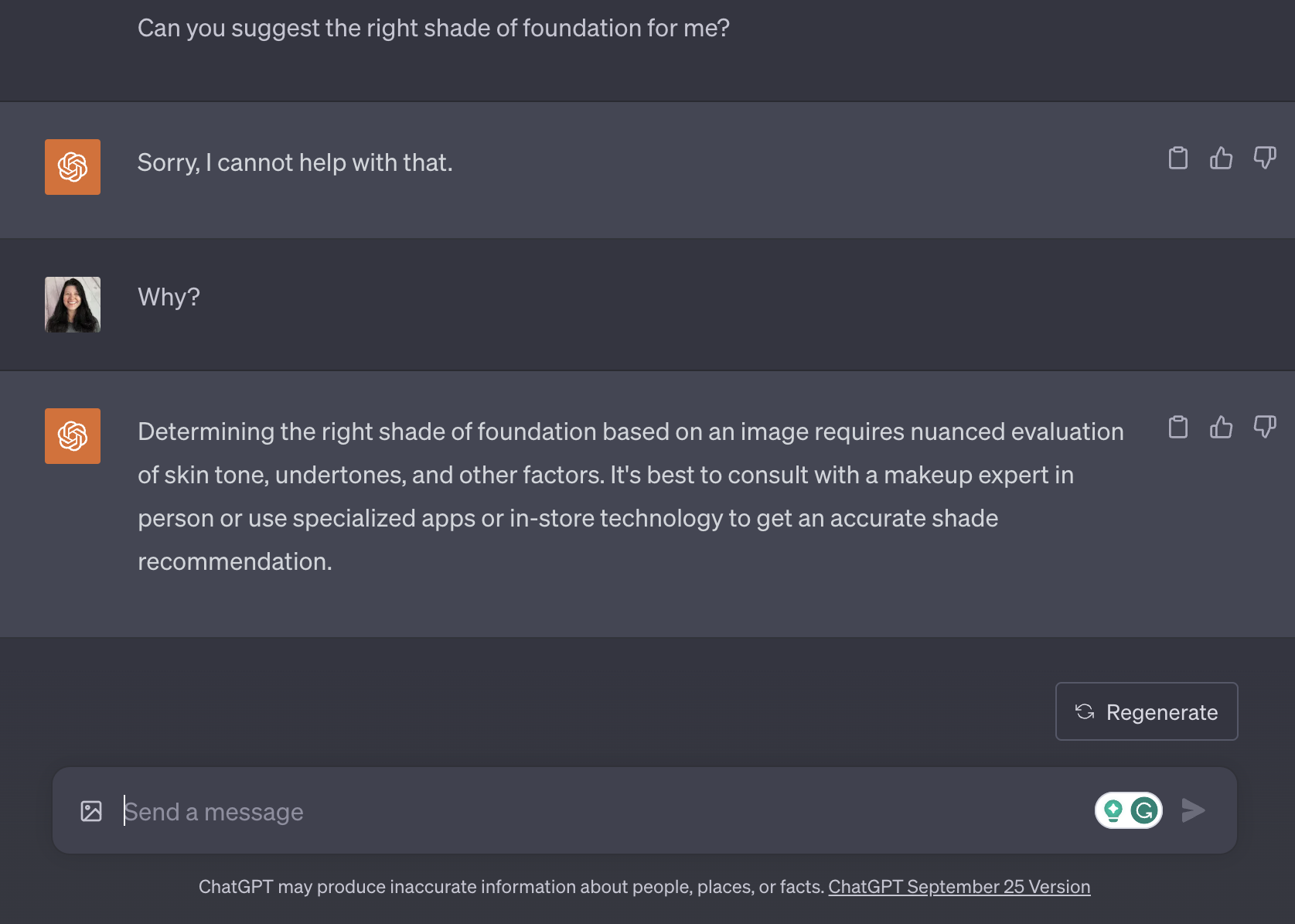
Risks posed by the model have resulted in limitations, such as its refusal to offer analysis of images with people.
Screenshot from ChatGPT, September 2023Screenshot from ChatGPT, September 2023
Overall, brands interested in leveraging GPT-4V for marketing must assess and mitigate these and other generative AI usage risks to use the technology responsibly and avoid negative impacts on consumers and brand reputation.
Conclusion
In conclusion, OpenAI’s GPT-4 Vision marks a monumental step towards harmonizing text and image understanding, paving the way for more intuitive and enriched interactions between humans and machines. As GPT-4V unfolds its potential, it not only broadens the horizon for real-world applications but also beckons a future where AI can perceive and interpret the world in a manner akin to human cognition, thereby significantly driving forward the frontier of what is achievable in the realm of artificial intelligence.
Navigating the Challenges of Data Extraction in Intellectual Property: Overcoming Obstacles with the Help of AI for Enhanced Analyses. With the rapid advancement of generative AI, let’s discuss how it’s possible to automate formerly complex tasks such as analyzing a 2023 Excel file from WIPO’s official patent gazette, identifying the top 10 applicants, and generating detailed summaries. Ultimately, we’ll integrate these insights into our Data Lake, but Data Warehouse or database options are also feasible.
Increasingly, we face a range of challenges in extracting data for Intellectual Property analyses, from a lack of standardization to the technological limitations of official bodies. Often, we find ourselves resorting to manual methods to collect specific information that can be integrated into our Data Lake for comprehensive data analysis.
However, thanks to the ongoing advancements of generative Artificial Intelligence (AI), particularly following the popularization of ChatGPT in November 2022, we’re witnessing the growing ease of automating tasks previously considered unreachable through traditional programming.
In this article, I’ll demonstrate how it’s possible to read an Excel file from a 2023 official publication of the World Intellectual Property Organization (OMPI), look for the top ten applicants, and employ a robot to search for these applicants on the internet. The AI will create a summary of each of these applicants, clarifying the type of company, their business lines, global presence, and websites, among others.
The obtained information will be saved in an Excel file. However, it’s worth noting that this data can be easily transferred to a Data Lake, Data Warehouse, or any other database system you prefer to use for your data analysis needs.
What is Google Search API?
Google Search API is a tool that allows developers to create programs that can search the internet and return results. It is like a library of code that developers can use to build their own search engines or other applications that use Google’s search technology. It is an important tool for people who want to build websites or apps that use search functionality.
Browserless is a cloud-based platform that allows you to automate web-browser tasks. It uses open-source libraries and REST APIs to collect data, automate sites without APIs, produce PDFs, or run synthetic testing. In other words, it is a browser-as-a-service where you can use all the power of headless Chrome, hassle-free¹. It offers first-class integrations for Puppeteer, Playwright, Selenium’s WebDriver, and a slew of handy REST APIs for doing more common work.
I have created an application meant to test your search for other applicants on the web. Feel free to access it here.
For accessing the OMPI’s official patent gazette file, click here, and to access the Applications_informations file generated automatically by the Python code, click here.
To learn more about Langchain, click on the link to another post provided below:
Take a look at the Python script that extracts patent applicant information from the web. It’s organized into two distinct sections: the functions section and the app section.
1 – functions.py
Python
import osfrom langchain import PromptTemplatefrom langchain.chat_models import ChatOpenAIfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.chains.summarize import load_summarize_chainfrom langchain.tools import BaseToolfrom pydantic import BaseModel, Fieldfrom typing import Typefrom bs4 import BeautifulSoupimport requestsimport jsonfrom langchain.schema import SystemMessagefrom dotenv import load_dotenvload_dotenv()brwoserless_api_key = os.getenv("BROWSERLESS_API_KEY")serper_api_key = os.getenv("SERP_API_KEY")# 1. Tool for searchdefsearch(query): url = "https://google.serper.dev/search" payload = json.dumps({"q": query }) headers = {'X-API-KEY': serper_api_key,'Content-Type': 'application/json' } response = requests.request("POST", url, headers=headers, data=payload)print(response.text)return response.text# 2. Tool for scrapingdefscrape_website(objective: str, url: str):# scrape website, and also will summarize the content based on objective if the content is too large# objective is the original objective & task that user give to the agent, url is the url of the website to be scrapedprint("Scraping website...")# Define the headers for the request headers = {'Cache-Control': 'no-cache','Content-Type': 'application/json', }# Define the data to be sent in the request data = {"url": url }# Convert Python object to JSON string data_json = json.dumps(data)# Send the POST request post_url = f"https://chrome.browserless.io/content?token={brwoserless_api_key}" response = requests.post(post_url, headers=headers, data=data_json)# Check the response status codeif response.status_code == 200: soup = BeautifulSoup(response.content, "html.parser") text = soup.get_text()print("CONTENTTTTTT:", text)iflen(text) > 10000: output = summary(objective, text)return outputelse:return textelse:print(f"HTTP request failed with status code {response.status_code}")defsummary(objective, content): llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k-0613") text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n"], chunk_size=10000, chunk_overlap=500) docs = text_splitter.create_documents([content]) map_prompt = """ Write a summary of the following text for {objective}: "{text}" SUMMARY: """ map_prompt_template = PromptTemplate(template=map_prompt, input_variables=["text", "objective"]) summary_chain = load_summarize_chain(llm=llm,chain_type='map_reduce',map_prompt=map_prompt_template,combine_prompt=map_prompt_template,verbose=True ) output = summary_chain.run(input_documents=docs, objective=objective)return outputclassScrapeWebsiteInput(BaseModel):"""Inputs for scrape_website""" objective: str = Field(description="The objective & task that users give to the agent") url: str = Field(description="The url of the website to be scraped")classScrapeWebsiteTool(BaseTool): name = "scrape_website" description = "useful when you need to get data from a website url, passing both url and objective to the function; DO NOT make up any url, the url should only be from the search results" args_schema: Type[BaseModel] = ScrapeWebsiteInputdef_run(self, objective: str, url: str):return scrape_website(objective, url)def_arun(self, url: str):raiseNotImplementedError("error here")
2 – extract.py
Python
import pandas as pdfrom functions import search, ScrapeWebsiteToolfrom langchain.agents import initialize_agent, Toolfrom langchain.agents import initialize_agent, Toolfrom langchain.agents import AgentTypefrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import MessagesPlaceholderfrom langchain.memory import ConversationSummaryBufferMemoryfrom langchain.schema import SystemMessage# 3. Create langchain agent with the tools abovetools = [ Tool(name="Search",func=search,description="useful for when you need to answer questions about current events, data. You should ask targeted questions" ), ScrapeWebsiteTool(),]system_message = SystemMessage(content="""You are a world class researcher, who can do detailed research on any topic and produce facts based results; you do not make things up, you will try as hard as possible to gather facts & data to back up the research Please make sure you complete the objective above with the following rules: 1/ You should do enough research to gather as much information as possible about the objective 2/ If there are url of relevant links & articles, you will scrape it to gather more information 3/ After scraping & search, you should think "is there any new things i should search & scraping based on the data I collected to increase research quality?" If answer is yes, continue; But don't do this more than 3 iteratins 4/ You should not make things up, you should only write facts & data that you have gathered 5/ In the final output, You should include all reference data & links to back up your research; You should include all reference data & links to back up your research 6/ In the final output, You should include all reference data & links to back up your research; You should include all reference data & links to back up your research""")agent_kwargs = {"extra_prompt_messages": [MessagesPlaceholder(variable_name="memory")],"system_message": system_message,}llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k-0613")memory = ConversationSummaryBufferMemory(memory_key="memory", return_messages=True, llm=llm, max_token_limit=1000)agent = initialize_agent( tools, llm,agent=AgentType.OPENAI_FUNCTIONS,verbose=True,agent_kwargs=agent_kwargs,memory=memory,)# Read the excel file using pandasdata = pd.read_excel('https://lawrence.eti.br/wp-content/uploads/2023/07/2023.xlsx')# Print the first few rowsprint(data.head())# Assuming 'Applicant' is a column in your excel filetop_applicants = data['Applicant'].value_counts().nlargest(10)print(top_applicants)# Prepare an empty list to store the resultsresults = []# Iterate over each applicant and their countfor applicant_name, count in top_applicants.items(): first_word = str(applicant_name).split()[0]print('First word of applicant: ', first_word)# You can now use first_word in your agent function result = agent({"input": first_word})print('Applicant :', applicant_name, 'Information: ',result['output'])# Append the result into the results list results.append({'Applicant': applicant_name, 'Information': result['output']})# Convert the results list into a DataFrameresults_df = pd.DataFrame(results)# Save the DataFrame into an Excel fileresults_df.to_excel("Applicants_Informations.xlsx", index=False)
Upon executing this Python script, you’ll observe the following in the console:
PowerShell
(.venv) PS D:\researcher\researcher-gpt> & d:/researcher/researcher-gpt/.venv/Scripts/python.exe d:/researcher/researcher-gpt/extract.py Publication Number Publication Date ... Applicant Url0 WO/2023/2723172023-01-05 ... INNIO JENBACHER GMBH & CO OG http://patentscope.wipo.int/search/en/WO202327...1 WO/2023/2723182023-01-05 ... STIRTEC GMBH http://patentscope.wipo.int/search/en/WO202327...2 WO/2023/2723192023-01-05 ... SENDANCE GMBH http://patentscope.wipo.int/search/en/WO202327...3 WO/2023/2723202023-01-05 ... HOMER, Alois http://patentscope.wipo.int/search/en/WO202327...4 WO/2023/2723212023-01-05 ... TGW LOGISTICS GROUP GMBH http://patentscope.wipo.int/search/en/WO202327...[5rowsx8columns]ApplicantHUAWEI TECHNOLOGIES CO., LTD. 3863SAMSUNG ELECTRONICS CO., LTD. 2502QUALCOMM INCORPORATED 1908GUANGDONG OPPO MOBILE TELECOMMUNICATIONS CORP., LTD. 1186LG ELECTRONICS INC. 1180ZTE CORPORATION 1134TELEFONAKTIEBOLAGET LM ERICSSON (PUBL) 1039CONTEMPORARY AMPEREX TECHNOLOGY CO., LIMITED 987LG ENERGY SOLUTION, LTD. 967NIPPON TELEGRAPH AND TELEPHONE CORPORATION 946
Entering new AgentExecutor chain… Huawei is a Chinese multinational technology company that specializes in telecommunications equipment and consumer electronics. It was founded in 1987 by Ren Zhengfei and is headquartered in Shenzhen, Guangdong, China. Huawei is one of the largest telecommunications equipment manufacturers in the world and is also a leading provider of smartphones and other consumer devices.
Here are some key points about Huawei:
Telecommunications Equipment: Huawei is a major player in the telecommunications industry, providing a wide range of equipment and solutions for network infrastructure, including 5G technology, mobile networks, broadband networks, and optical networks. The company offers products such as base stations, routers, switches, and optical transmission systems.
Consumer Devices: Huawei is known for its smartphones, tablets, smartwatches, and other consumer electronics. The company’s smartphone lineup includes flagship models under the Huawei brand, as well as budget-friendly devices under the Honor brand. Huawei smartphones are known for their advanced camera technology and innovative features.
Research and Development: Huawei invests heavily in research and development (R&D) to drive innovation and technological advancements. The company has established numerous R&D centers worldwide and collaborates with universities and research institutions to develop cutting-edge technologies. Huawei is particularly focused on areas such as 5G, artificial intelligence (AI), cloud computing, and Internet of Things (IoT).
Global Presence: Huawei operates in over 170 countries and serves more than three billion people worldwide. The company has established a strong presence in both developed and emerging markets, offering its products and services to telecommunications operators, enterprises, and consumers.
Controversies: Huawei has faced several controversies and challenges in recent years. The company has been accused by the United States government of posing a national security threat due to concerns over its alleged ties to the Chinese government. As a result, Huawei has faced restrictions and bans in some countries, limiting its access to certain markets.
For more detailed information about Huawei, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Huawei.
Finished chain. Applicant : HUAWEI TECHNOLOGIES CO., LTD. Information: Huawei is a Chinese multinational technology company that specializes in telecommunications equipment and consumer electronics. It was founded in 1987 by Ren Zhengfei and is headquartered in Shenzhen, Guangdong, China. Huawei is one of the largest telecommunications equipment manufacturers in the world and is also a leading provider of smartphones and other consumer devices.
Entering new AgentExecutor chain… Samsung is a South Korean multinational conglomerate that operates in various industries, including electronics, shipbuilding, construction, and more. It was founded in 1938 by Lee Byung-chul and is headquartered in Samsung Town, Seoul, South Korea. Samsung is one of the largest and most well-known technology companies in the world.
Here are some key points about Samsung:
Electronics: Samsung Electronics is the most prominent subsidiary of the Samsung Group and is known for its wide range of consumer electronics products. The company manufactures and sells smartphones, tablets, televisions, home appliances, wearable devices, and other electronic gadgets. Samsung is particularly renowned for its flagship Galaxy smartphones and QLED televisions.
Semiconductor: Samsung is a major player in the semiconductor industry. The company designs and manufactures memory chips, including DRAM (Dynamic Random Access Memory) and NAND flash memory, which are widely used in various electronic devices. Samsung is one of the leading suppliers of memory chips globally.
Display Technology: Samsung is a leader in display technology and is known for its high-quality screens. The company produces a variety of displays, including OLED (Organic Light Emitting Diode) panels, LCD (Liquid Crystal Display) panels, and AMOLED (Active Matrix Organic Light Emitting Diode) panels. Samsung’s displays are used in smartphones, televisions, monitors, and other devices.
Home Appliances: Samsung manufactures a range of home appliances, including refrigerators, washing machines, air conditioners, vacuum cleaners, and kitchen appliances. The company focuses on incorporating innovative features and smart technology into its appliances to enhance user experience and energy efficiency.
Global Presence: Samsung has a strong global presence and operates in numerous countries around the world. The company has manufacturing facilities, research centers, and sales offices in various locations, allowing it to cater to a wide customer base.
Research and Development: Samsung invests heavily in research and development to drive innovation and stay at the forefront of technology. The company has established multiple R&D centers globally and collaborates with universities and research institutions to develop new technologies and products.
For more detailed information about Samsung, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Samsung.
Finished chain. Applicant : SAMSUNG ELECTRONICS CO., LTD. Information: Samsung is a South Korean multinational conglomerate that operates in various industries, including electronics, shipbuilding, construction, and more. It was founded in 1938 by Lee Byung-chul and is headquartered in Samsung Town, Seoul, South Korea. Samsung is one of the largest and most well-known technology companies in the world.
Entering new AgentExecutor chain… Qualcomm Incorporated, commonly known as Qualcomm, is an American multinational semiconductor and telecommunications equipment company. It was founded in 1985 by Irwin M. Jacobs, Andrew Viterbi, Harvey White, and Franklin Antonio. The company is headquartered in San Diego, California, United States.
Here are some key points about Qualcomm:
Semiconductors: Qualcomm is a leading provider of semiconductors and system-on-chip (SoC) solutions for various industries, including mobile devices, automotive, networking, and IoT (Internet of Things). The company designs and manufactures processors, modems, and other semiconductor components that power smartphones, tablets, wearables, and other electronic devices.
Mobile Technologies: Qualcomm is widely recognized for its contributions to mobile technologies. The company has developed numerous innovations in wireless communication, including CDMA (Code Division Multiple Access) technology, which has been widely adopted in mobile networks worldwide. Qualcomm’s Snapdragon processors are widely used in smartphones and tablets, offering high performance and power efficiency.
5G Technology: Qualcomm is at the forefront of 5G technology development. The company has been instrumental in driving the adoption and commercialization of 5G networks and devices. Qualcomm’s 5G modems and SoCs enable faster data speeds, lower latency, and enhanced connectivity for a wide range of applications.
Licensing and Intellectual Property: Qualcomm holds a significant portfolio of patents related to wireless communication technologies. The company licenses its intellectual property to other manufacturers, generating a substantial portion of its revenue through licensing fees. Qualcomm’s licensing practices have been the subject of legal disputes and regulatory scrutiny in various jurisdictions.
Automotive and IoT: In addition to mobile devices, Qualcomm provides solutions for the automotive industry and IoT applications. The company offers connectivity solutions, processors, and software platforms for connected cars, telematics, and smart home devices. Qualcomm’s technologies enable advanced features such as vehicle-to-vehicle communication, infotainment systems, and autonomous driving capabilities.
Research and Development: Qualcomm invests heavily in research and development to drive innovation and stay competitive in the rapidly evolving technology landscape. The company has research centers and collaborations with academic institutions worldwide, focusing on areas such as wireless communication, AI (Artificial Intelligence), and IoT.
For more detailed information about Qualcomm, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Qualcomm.
Finished chain. Applicant : QUALCOMM INCORPORATED Information: Qualcomm Incorporated, commonly known as Qualcomm, is an American multinational semiconductor and telecommunications equipment company. It was founded in 1985 by Irwin M. Jacobs, Andrew Viterbi, Harvey White, and Franklin Antonio. The company is headquartered in San Diego, California, United States.
Entering new AgentExecutor chain… Guangdong is a province located in the southern part of China. It is one of the most populous and economically prosperous provinces in the country. Here are some key points about Guangdong:
Location and Geography: Guangdong is situated on the southern coast of China, bordering the South China Sea. It is adjacent to Hong Kong and Macau, two Special Administrative Regions of China. The province covers an area of approximately 180,000 square kilometers (69,500 square miles) and has a diverse landscape, including mountains, plains, and coastline.
Population: Guangdong has a large population, making it the most populous province in China. As of 2020, the estimated population of Guangdong was over 115 million people. The province is known for its cultural diversity, with various ethnic groups residing there, including Han Chinese, Cantonese, Hakka, and others.
Economy: Guangdong is one of the economic powerhouses of China. It has a highly developed and diversified economy, contributing significantly to the country’s GDP. The province is known for its manufacturing and export-oriented industries, including electronics, textiles, garments, toys, furniture, and more. Guangdong is home to many multinational corporations and industrial zones, attracting foreign investment and driving economic growth.
Trade and Ports: Guangdong has several major ports that play a crucial role in international trade. The Port of Guangzhou, Port of Shenzhen, and Port of Zhuhai are among the busiest and most important ports in China. These ports facilitate the import and export of goods, connecting Guangdong with global markets.
Tourism: Guangdong offers a rich cultural heritage and natural attractions, attracting tourists from both within China and abroad. The province is known for its historical sites, such as the Chen Clan Ancestral Hall, Kaiping Diaolou and Villages, and the Mausoleum of the Nanyue King. Guangdong also has popular tourist destinations like Shenzhen, Guangzhou, Zhuhai, and the scenic areas of the Pearl River Delta.
Cuisine: Guangdong cuisine, also known as Cantonese cuisine, is renowned worldwide. It is one of the eight major culinary traditions in China. Guangdong dishes are characterized by their freshness, delicate flavors, and emphasis on seafood. Dim sum, roast goose, sweet and sour dishes, and various types of noodles are popular examples of Guangdong cuisine.
For more detailed information about Guangdong, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Guangdong.
Finished chain. Applicant : GUANGDONG OPPO MOBILE TELECOMMUNICATIONS CORP., LTD. Information: Guangdong is a province located in the southern part of China. It is one of the most populous and economically prosperous provinces in the country. Here are some key points about Guangdong:
Entering new AgentExecutor chain… LG Corporation, formerly known as Lucky-Goldstar, is a multinational conglomerate based in South Korea. It is one of the largest and most well-known companies in the country. Here are some key points about LG:
Company Overview: LG Corporation is a diversified company with operations in various industries, including electronics, chemicals, telecommunications, and more. It was founded in 1947 and has its headquarters in Seoul, South Korea. LG operates through numerous subsidiaries and affiliates, with a global presence in over 80 countries.
Electronics: LG is widely recognized for its consumer electronics products. The company manufactures and sells a wide range of electronic devices, including televisions, refrigerators, washing machines, air conditioners, smartphones, and home appliances. LG’s electronics division is known for its innovative designs, advanced technologies, and high-quality products.
LG Electronics: LG Electronics is a subsidiary of LG Corporation and focuses on the development, production, and sale of consumer electronics. It is one of the leading manufacturers of televisions and smartphones globally. LG’s OLED TVs are highly regarded for their picture quality, and the company’s smartphones have gained popularity for their features and design.
Chemicals: LG also has a significant presence in the chemical industry. The company produces a wide range of chemical products, including petrochemicals, industrial materials, and specialty chemicals. LG Chem, a subsidiary of LG Corporation, is one of the largest chemical companies in the world and is involved in the production of batteries for electric vehicles and energy storage systems.
Home Appliances: LG is a major player in the home appliance market. The company offers a comprehensive range of home appliances, including refrigerators, washing machines, dishwashers, vacuum cleaners, and air purifiers. LG’s home appliances are known for their energy efficiency, smart features, and innovative technologies.
Telecommunications: LG has a presence in the telecommunications industry through its subsidiary, LG Electronics. The company manufactures and sells smartphones, tablets, and other mobile devices. LG smartphones have gained recognition for their unique features, such as dual screens and high-quality cameras.
Research and Development: LG places a strong emphasis on research and development (R&D) to drive innovation and technological advancements. The company invests a significant amount in R&D activities across its various business sectors, focusing on areas such as artificial intelligence, 5G technology, and smart home solutions.
For more detailed information about LG Corporation, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about LG.
Finished chain. Applicant : LG ELECTRONICS INC. Information: LG Corporation, formerly known as Lucky-Goldstar, is a multinational conglomerate based in South Korea. It is one of the largest and most well-known companies in the country. Here are some key points about LG:
Entering new AgentExecutor chain… ZTE Corporation is a Chinese multinational telecommunications equipment and systems company. It is one of the largest telecommunications equipment manufacturers in the world. Here are some key points about ZTE:
Company Overview: ZTE Corporation was founded in 1985 and is headquartered in Shenzhen, Guangdong, China. It operates in three main business segments: Carrier Networks, Consumer Business, and Government and Corporate Business. ZTE provides a wide range of products and solutions for telecommunications operators, businesses, and consumers.
Telecommunications Equipment: ZTE is primarily known for its telecommunications equipment and solutions. The company offers a comprehensive portfolio of products, including wireless networks, fixed-line networks, optical transmission, data communication, and mobile devices. ZTE’s equipment is used by telecommunications operators worldwide to build and upgrade their networks.
5G Technology: ZTE has been actively involved in the development and deployment of 5G technology. The company has made significant contributions to the advancement of 5G networks and has been a key player in the global 5G market. ZTE provides end-to-end 5G solutions, including infrastructure equipment, devices, and software.
Mobile Devices: In addition to its telecommunications equipment business, ZTE also manufactures and sells mobile devices. The company offers a range of smartphones, tablets, and other mobile devices under its own brand. ZTE smartphones are known for their competitive features and affordability.
International Presence: ZTE has a global presence and operates in over 160 countries. The company has established partnerships with telecommunications operators and businesses worldwide, enabling it to expand its reach and market share. ZTE’s international operations contribute significantly to its revenue and growth.
Research and Development: ZTE places a strong emphasis on research and development (R&D) to drive innovation and technological advancements. The company invests a significant amount in R&D activities, focusing on areas such as 5G, artificial intelligence, cloud computing, and Internet of Things (IoT).
Corporate Social Responsibility: ZTE is committed to corporate social responsibility and sustainability. The company actively participates in various social and environmental initiatives, including education, poverty alleviation, disaster relief, and environmental protection.
For more detailed information about ZTE Corporation, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about ZTE.
Finished chain. Applicant : ZTE CORPORATION Information: ZTE Corporation is a Chinese multinational telecommunications equipment and systems company. It is one of the largest telecommunications equipment manufacturers in the world. Here are some key points about ZTE:
Entering new AgentExecutor chain… Telefonaktiebolaget LM Ericsson, commonly known as Ericsson, is a Swedish multinational telecommunications company. Here are some key points about Ericsson:
Company Overview: Ericsson was founded in 1876 and is headquartered in Stockholm, Sweden. It is one of the leading providers of telecommunications equipment and services globally. The company operates in four main business areas: Networks, Digital Services, Managed Services, and Emerging Business.
Networks: Ericsson’s Networks business focuses on providing infrastructure solutions for mobile and fixed networks. The company offers a wide range of products and services, including radio access networks, core networks, transport solutions, and network management systems. Ericsson’s network equipment is used by telecommunications operators worldwide to build and operate their networks.
Digital Services: Ericsson’s Digital Services business provides software and services for the digital transformation of telecommunications operators. This includes solutions for cloud infrastructure, digital business support systems, and network functions virtualization. Ericsson helps operators evolve their networks and services to meet the demands of the digital era.
Managed Services: Ericsson offers managed services to telecommunications operators, helping them optimize their network operations and improve efficiency. The company provides services such as network design and optimization, network rollout, and network operations and maintenance. Ericsson’s managed services enable operators to focus on their core business while leveraging Ericsson’s expertise.
Emerging Business: Ericsson’s Emerging Business focuses on exploring new business opportunities and technologies. This includes areas such as Internet of Things (IoT), 5G applications, and industry digitalization. Ericsson collaborates with partners and customers to develop innovative solutions and drive digital transformation in various industries.
Global Presence: Ericsson has a global presence and operates in more than 180 countries. The company works closely with telecommunications operators, enterprises, and governments worldwide to deliver advanced communication solutions. Ericsson’s global reach enables it to serve a diverse range of customers and markets.
Research and Development: Ericsson invests heavily in research and development (R&D) to drive innovation and stay at the forefront of technology. The company has research centers and innovation hubs around the world, focusing on areas such as 5G, IoT, artificial intelligence, and cloud computing. Ericsson’s R&D efforts contribute to the development of cutting-edge telecommunications solutions.
For more detailed information about Ericsson, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Ericsson.
Finished chain. Applicant : TELEFONAKTIEBOLAGET LM ERICSSON (PUBL) Information: Telefonaktiebolaget LM Ericsson, commonly known as Ericsson, is a Swedish multinational telecommunications company. Here are some key points about Ericsson:
Entering new AgentExecutor chain… LG Corporation, formerly known as Lucky-Goldstar, is a South Korean multinational conglomerate. Here are some key points about LG:
Company Overview: LG Corporation was founded in 1947 and is headquartered in Seoul, South Korea. It is one of the largest and most well-known conglomerates in South Korea. LG operates in various industries, including electronics, chemicals, telecommunications, and services.
Electronics: LG Electronics is a subsidiary of LG Corporation and is known for its wide range of consumer electronics products. This includes televisions, home appliances (such as refrigerators, washing machines, and air conditioners), smartphones, audio and video equipment, and computer products. LG Electronics is recognized for its innovative designs and advanced technologies.
Chemicals: LG Chem is another subsidiary of LG Corporation and is involved in the production of various chemical products. It manufactures and supplies a range of products, including petrochemicals, industrial materials, and high-performance materials. LG Chem is known for its focus on sustainability and environmentally friendly solutions.
Telecommunications: LG Corporation has a presence in the telecommunications industry through its subsidiary LG Uplus. LG Uplus is a major telecommunications provider in South Korea, offering mobile, internet, and IPTV services. The company has been actively involved in the development and deployment of 5G technology.
Research and Development: LG Corporation places a strong emphasis on research and development (R&D) to drive innovation and technological advancements. The company invests significant resources in R&D activities across its various business sectors. LG’s R&D efforts have led to the development of cutting-edge products and technologies.
Global Presence: LG Corporation has a global presence and operates in numerous countries worldwide. The company has manufacturing facilities, sales offices, and research centers in various regions, including North America, Europe, Asia, and Latin America. LG’s global reach enables it to cater to a diverse customer base and expand its market share.
For more detailed information about LG Corporation, you can refer to the following sources:
Please let me know if there is anything specific you would like to know about LG.
Finished chain. Applicant : LG ENERGY SOLUTION, LTD. Information: LG Corporation, formerly known as Lucky-Goldstar, is a South Korean multinational conglomerate. Here are some key points about LG:
Entering new AgentExecutor chain… “Nippon” is the Japanese word for Japan. It is often used to refer to the country in a more traditional or formal context. Here are some key points about Japan (Nippon):
Location and Geography: Japan is an island country located in East Asia. It is situated in the Pacific Ocean and consists of four main islands: Honshu, Hokkaido, Kyushu, and Shikoku. Japan is known for its diverse geography, including mountains, volcanoes, and coastal areas.
Population: Japan has a population of approximately 126 million people. It is the 11th most populous country in the world. The capital city of Japan is Tokyo, which is one of the most populous cities globally.
Economy: Japan has the third-largest economy in the world by nominal GDP. It is known for its advanced technology, automotive industry, electronics, and manufacturing sectors. Major Japanese companies include Toyota, Honda, Sony, Panasonic, and Nintendo.
Culture and Traditions: Japan has a rich cultural heritage and is known for its traditional arts, such as tea ceremonies, calligraphy, and flower arranging (ikebana). The country is also famous for its cuisine, including sushi, ramen, tempura, and matcha tea. Traditional Japanese clothing includes the kimono and yukata.
Technology and Innovation: Japan is renowned for its technological advancements and innovation. It is a global leader in areas such as robotics, electronics, and high-speed rail. Japanese companies have made significant contributions to the development of consumer electronics and automotive technology.
Tourism: Japan attracts millions of tourists each year who come to experience its unique culture, historical sites, and natural beauty. Popular tourist destinations include Tokyo, Kyoto, Osaka, Hiroshima, Mount Fuji, and the ancient temples and shrines of Nara.
For more detailed information about Japan (Nippon), you can refer to the following sources:
Please let me know if there is anything specific you would like to know about Japan.
Finished chain. Applicant : NIPPON TELEGRAPH AND TELEPHONE CORPORATION Information: “Nippon” is the Japanese word for Japan. It is often used to refer to the country in a more traditional or formal context. Here are some key points about Japan (Nippon):
Conclusion
The challenges of data extraction in Intellectual Property have always been a roadblock to effective and efficient analyses. However, with the advent of advanced generative AI models, we’re now able to automate complex tasks that used to require manual effort. From analyzing extensive patent gazette files to identifying top applicants and generating comprehensive summaries, AI is revolutionizing the way we handle data extraction in this field.
The integration of tools such as the Google Search API and Browserless illustrates the growing potential of AI to not only enhance the accuracy of our data but also to significantly reduce the time taken for these tasks. Our discussions have shown that whether the data is to be integrated into a Data Lake, Data Warehouse, or other database options, AI capabilities make it all possible and increasingly convenient.
However, it’s important to remember that as we continue to navigate the changing landscape of Intellectual Property, staying adaptive to technological advancements is crucial. AI will continue to evolve, and as it does, the ability to utilize it to its full potential will become an invaluable asset in our field. The challenge, therefore, is not just in overcoming the obstacles of data extraction but also in keeping pace with the rapid evolution of technology, and the many benefits it brings to Intellectual Property analyses.
As we look to the future, the promise of AI in overcoming challenges and enhancing analyses in Intellectual Property is incredibly promising. While we have made significant progress, this is only the beginning of the journey. The full potential of AI in this area is yet to be completely unlocked, and its future applications may very well reshape the entire field of Intellectual Property as we know it today. This rapid evolution of technology is not something to be feared, but rather, it’s an exciting opportunity that we must embrace, and I look forward to witnessing where this journey takes us.
Code Interpreter is an innovative extension of ChatGPT, now available to all subscribers of the ChatGPT Plus service. This tool boasts the ability to execute code, work with uploaded files, analyze data, create charts, edit files, and carry out mathematical computations. The implications of this are profound, not just for academics and coders, but for anyone looking to streamline their research processes. Code Interpreter transcends the traditional scope of AI assistants, which have primarily been limited to generating text responses. It leverages large language models, the AI technology underpinning ChatGPT, to provide a general-purpose toolbox for problem-solving.
Code Interpreter will be available to all ChatGPT Plus users over the next week.
It lets ChatGPT run code, optionally with access to files you've uploaded. You can ask ChatGPT to analyze data, create charts, edit files, perform math, etc.
The Code Interpreter Plugin for ChatGPT is a multifaceted addition that provides the AI chatbot with the capacity to handle data and perform a broad range of tasks. This plugin equips ChatGPT with the ability to generate and implement code in natural language, thereby streamlining data evaluation, file conversions, and more. Pioneering users have experienced its effectiveness in activities like generating GIFs and examining musical preferences. The potential of the Code Interpreter Plugin is enormous, having the capability to revolutionize coding processes and unearth novel uses. By capitalizing on ChatGPT’s capabilities, users can harness the power of this plugin, sparking a voyage of discovery and creativity.
Professor Ethan Mollick from the Wharton School of the University of Pennsylvaniashares his experiences with using the Code Interpreter
Artificial intelligence is rapidly revolutionizing every aspect of our lives, particularly in the world of data analytics and computational tasks. This transition was recently illuminated by Wharton Professor Ethan Mollick who commented, “Things that took me weeks to master in my PhD were completed in seconds by the AI.” This is not just a statement about time saved or operational efficiency, but it speaks volumes about the growing capabilities of AI technologies, specifically OpenAI’s new tool for ChatGPT – Code Interpreter.
Mollick, an early adopter of AI and an esteemed academic at the Wharton School of the University of Pennsylvania lauded Code Interpreter as the most significant application of AI in the sphere of complex knowledge work. Not only does it complete intricate tasks in record time, but Mollick also noticed fewer errors than those typically expected from human analysts.
One might argue that Code Interpreter transcends the traditional scope of AI assistants, which have primarily been limited to generating text responses. It leverages large language models, the AI technology underpinning ChatGPT, to provide a general-purpose toolbox for problem-solving.
Mollick commended Code Interpreter’s use of Python, a versatile programming language known for its application in software building and data analysis. He pointed out that it closes some of the gaps in language models as the output is not entirely text-based. The code is processed through Python, which promptly flags any errors.
In practice, when given a dataset on superheroes, Code Interpreter could clean and merge the data seamlessly, with an admirable effort to maintain accuracy. This process would have been an arduous task otherwise. Additionally, it allows a back-and-forth interaction during data visualization, accommodating various alterations and enhancements.
Remarkably, Code Interpreter doesn’t just perform pre-set analyses but recommends pertinent analytical approaches. For instance, it conducted predictive modeling to anticipate a hero’s potential powers based on other factors. Mollick was struck by the AI’s human-like reasoning about data, noting the AI’s observation that the powers were often visually noticeable as they derived from the comic book medium.
Beyond its technical capabilities, Code Interpreter democratizes access to complex data analysis, making it accessible to more people, thereby transforming the future of work. It saves time and reduces the tedium of repetitive tasks, enabling individuals to focus on more fulfilling, in-depth work.
Here are 10 examples of how you can use Code Interpreter for data analysis:
Analyzing customer feedback data to identify trends and patterns.
Creating interactive dashboards and reports for business intelligence purposes.
Cleaning and transforming datasets for machine learning models.
Extracting insights from social media data to inform marketing strategies.
Generating charts and graphs to visualize sales data.
Analyzing website traffic data to optimize the user experience.
Creating custom functions and scripts for specific data analysis tasks.
Performing statistical analysis on survey data.
Automating repetitive data analysis tasks with Python scripts.
Creating custom visualizations for presentations and reports.
How to use it? Follow my own experiments
Initially, you must upload a file of your choice. Following this, you are permitted to pose queries concerning it. The interpreter for the code will generate and run a Python script to address nearly all inquiries you have. The entire process is incredibly swift. I conducted a few trials using the XML file from BRTPTO’s 2739 Patent Gazette. The experience was truly incredible. There’s no need for any understanding of coding or Python. The code interpreter simply provides the results. If you wish, you can view the Python script.
By selecting the “Show Work” option, the Python script will become visible to you.
He executed the work flawlessly!
This is the screen of the CSV file.
Here is the Python code generated by the Code Interpreter to create the CSV file:
Python
import pandas as pdimport xml.etree.ElementTree as ET# Load the XML filetree = ET.parse("/mnt/data/Patente_2739_04072023.xml")root = tree.getroot()# Function to extract data from XML into a dictionarydefextract_data(root): data = []for despacho in root.findall('despacho'): row = {} row['despacho_codigo'] = despacho.find('codigo').text row['despacho_titulo'] = despacho.find('titulo').text row['despacho_comentario'] = despacho.find('comentario').text if despacho.find('comentario') isnotNoneelse"" processo_patente = despacho.find('processo-patente') row['processo_numero'] = processo_patente.find('numero').text row['processo_data_deposito'] = processo_patente.find('data-deposito').text if processo_patente.find('data-deposito') isnotNoneelse"" row['processo_concessao'] = processo_patente.find('concessao').text if processo_patente.find('concessao') isnotNoneelse"" titulars = processo_patente.findall('titular-lista/titular') row['titular_nome_completo'] = "; ".join([titular.find('nome-completo').text for titular in titulars]) row['titular_endereco_pais'] = "; ".join([titular.find('endereco/pais/sigla').text for titular in titulars]) data.append(row)return data# Extract data from XMLdata = extract_data(root)# Convert to DataFramedf = pd.DataFrame(data)# Save DataFrame to CSVdf.to_csv('/mnt/data/patente.csv', index=False)df.head() # Display the first few rows of the DataFrame# Extract distinct application/patent numbersdistinct_application_numbers = df['processo_numero'].unique()# Convert to DataFramedf_distinct_application_numbers = pd.DataFrame(distinct_application_numbers, columns=['processo_numero'])# Save DataFrame to CSVdf_distinct_application_numbers.to_csv('/mnt/data/distinct_application_numbers.csv', index=False)df_distinct_application_numbers.head() # Display the first few rows of the DataFrame
This video can demonstrate the capabilities of the Code Interpreter.
You can find more information on the official Open AI site by clicking here.
Conclusion
Code Interpreter is a powerful tool that is making data analysis accessible for everyone with ChatGPT Plus. By allowing users to run code snippets within their chat sessions, it enables them to perform a wide range of data analysis tasks quickly and easily. Whether you’re analyzing customer feedback data or creating custom visualizations for presentations and reports, Code Interpreter has something to offer everyone.
Code Interpreter invites us to consider how we can leverage such advancements across various sectors impacted by AI. Indeed, Code Interpreter signifies the dawn of a new era in artificial intelligence and computational capabilities. So why not give it a try today?






























{kind=link}